
Object detection models are an integral part of computer vision. They are trained to detect the presence of specific objects in an image or a video. Object detection models play an important role in developing new technologies, like autonomous driving on the road, animal monitoring in agriculture, and identifying people in restricted areas. It is one of the biggest accomplishments of deep learning, image processing, and artificial intelligence.
There are a variety of object detections models. However, not all the approaches manage to detect objects appropriately. You need to know the best ways to make your computer vision project successful. In this post, you will find 5 of the best object detection models. Now, let’s dive in.
What is an object detection model?
Object detection model is an expression of algorithm that helps you to identify a set of objects within an image or video. It provides you with detailed information about their position in the image. So, you can count the number of objects in a scene and track their precise locations.
Let’s think about an image where a woman is holding a cat with her hand, while another one is sitting right beside her. By using the object detection model, you can classify the types of objects found in the image.

The object detection model reveals that there are two types of objects: cat and person. Both of them are annotated. The boundaries are defined around the objects. So, you can determine their precise location.
AI engineers around the world are using various object detection models to solve real-world issues, like analyzing medical images of high-risk patients and helping doctors with making their decision on the necessary treatment. In this post, you will find 5 of the best object detection models that are widely being used across the globe.
R-CNN stands for Region-based Convolutional Neural Networks. It is a family of machine learning models used in computer vision. R-CNN can detect objects in any input image. Once the identification is done, it defines boundaries around the objects.
Before the arrival of R-CNN, the AI engineers were struggling with the other object detection models, like Exhaustive Search, which required high computation performance. Also, it took a long time to identify the best object positions. R-CNN solved this problem by utilizing Selective Search to extract around 2000 regions from the image, which are known as region proposals.
The region proposals are warped into a square. Then they are fed into a Convolutional Neural Network (CNN), which works as a feature extractor. Next, the extracted features are fed into a Support Vector Machine (SVM). Here, the presence of the object within the region proposal is classified.
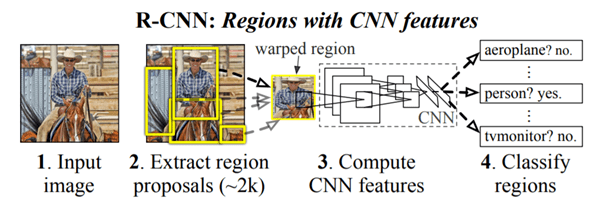
However, R-CNN is very slow. It takes 50 seconds to test an image.
You should consider R-CNN as the first method of object detection. You can use it to test other algorithms and their respective performance.
Fast R-CNN was introduced to address the drawback of R-CNN. The approach is pretty similar. However, there is a major difference. To generate the feature map, the entire image is fed to the CNN, rather than just the region proposals.
By analyzing the feature map, you can identify and warp the region of proposals into squares. Next, an RoI pooling layer is used to reshape the squares into a fixed size. As a result, they can be fed into a fully connected layer. Then you can use a softmax layer to predict the class of the proposed region. Also, you can predict the offset values for bounding boxes of objects.
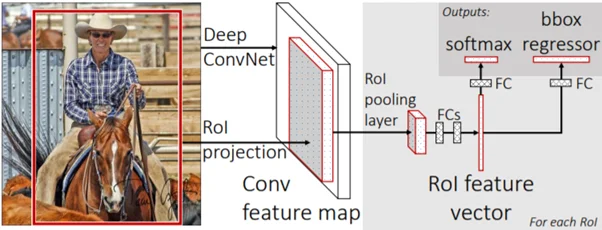
Fast R-CNN is significantly faster than R-CNN. The test time is just 2 seconds per image. So, it is very efficient at identifying objects quickly.
If you are required to predict the objects in the image within 2 seconds, you should strongly consider using Fast-RCNN.
Faster R-CNN enhances the performance of its predecessors tremendously. Instead of selective search, it utilizes Region Proposal Network (RPN) to eliminate the time-consuming process of selective search and boost the speed of processing images significantly.
Similar to Fast R-CNN, Faster R-CNN takes the entire image as an input to a convolutional network to generate a convolutional feature map. Instead of using the selective search algorithm, a separate network is used to predict the region proposals. It is known as RPN.
On the feature map, RPN generates a set of rectangular object proposals, which provides objectness scores as output. These values are then reshaped using the RoI pooling layer to classify the image within the proposed region. Also, it predicts the offset values for bounding boxes.
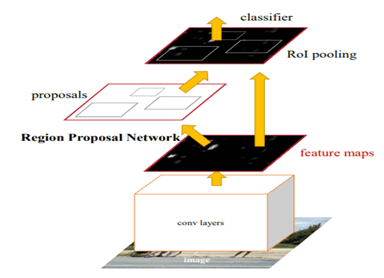
Faster R-CNN takes a little time to process the image. The testing time is only 0.2 second. As a result, it becomes the fastest object detection model of the R-CNN family.
You should use Faster R-CNN when it is required to identify the objects in the image in less than 1 second.
YOLO is an object detection model that utilizes a single convolutional network to predict the bounding boxes and their confidence scores. Here, you ‘You Look Only Once’ at the image to predict the location and class of the objects.
YOLO splits the input image into an SxS grid. The network outputs a class probability for each of the bounding boxes. Also, it provides offset values. The bounding boxes with the class probability above a threshold value are used to detect the object within the given image.
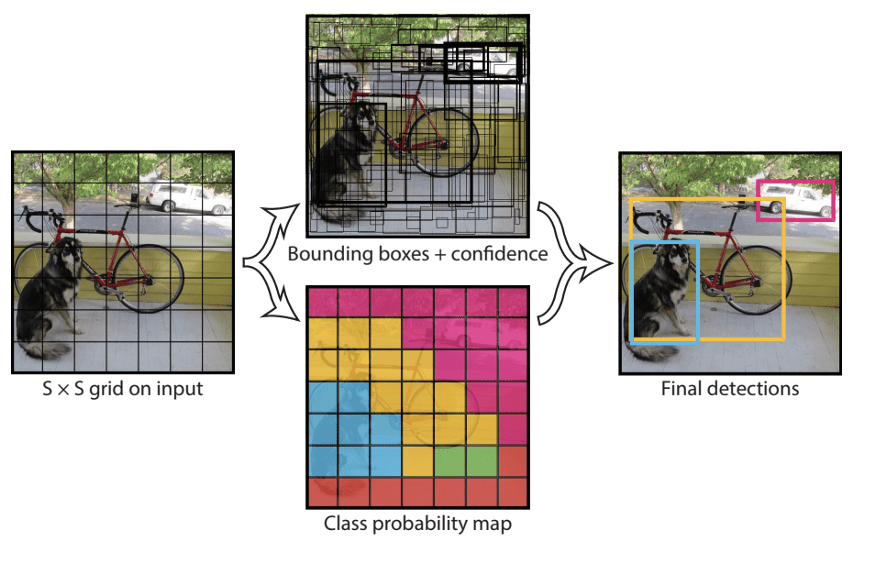
The computation and processing speed of YOLO are very high. It can detect objects in real-time at 45 frames per second. Also, the accuracy is very high.
If you need to identify the real-time objects with high accuracy, you should strongly consider using Yolo.
SSD stands for Single Shot Detector. It is one of the fastest methods for detecting objects in real-time. It is almost five times faster than the Faster R-CNN model. Instead of the region proposal network, SSD utilizes multi-scale features and default boxes to identify the objects quickly.
The Single Shot Detector works through three different stages. In the first stage, all the essential feature maps are extracted. The next step involves detecting heads to create the most appropriate bounding maps for all the feature maps. The third and final stage involves utilizing non-maximum suppression layers to reduce the error rate caused by repeated bounding boxes.
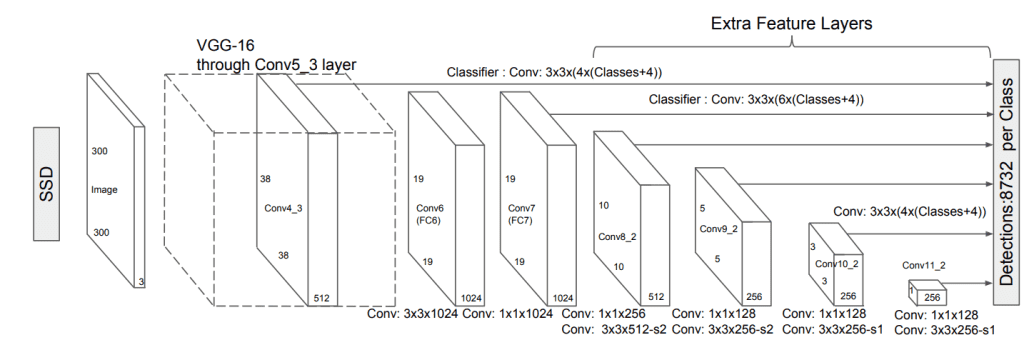
SSD is designed for detecting objects in real-time. The whole process runs at 7 frames per second.
You should use SSD to detect large objects in images in real-time where accuracy is not a big concern.
Choosing the best object detection model is very important for making your Computer Vision project successful. You can choose a variety of algorithms. However, not all of them can yield the best result. You need to know the right scenario of using them. By using the object detection models described in this post, you can locate the objects in an image or a video effectively. Make sure to utilize them in the appropriate situation as discussed in the article.


