
🔑 In 9 minutes you will learn:
- What YOLO means in computer vision
- Why the Speed of Object Detection is important
- Pros and cons of YOLO
YOLO is an acronym used in computer vision for You Only Look Once. It refers to an algorithm that uses neural networks to detect objects in images.
Since its debut in 2015, it has become the go-to object detection algorithm because of its speed and accuracy. Today, it is used in various applications to detect people, traffic signals, animals, parking meters, etc.
Also referred to as simulated neural networks (SNNs) or artificial neural networks (ANNs), neural networks are a series of algorithms that mimic the workings of the human brain to identify underlying relationships and patterns in a set of data. A neural network helps in clustering and classification; it helps with grouping unlabeled data based on similarities with the dataset used to train it.
Object detection, on the other hand, refers to an advanced type of image categorization in which a neural network detects objects in an image and draws bounding boxes around them. The detection includes identifying what class an object is and where within the image it is located.
You Only Look Once in YOLO means this object detection technique predicts the objects in an image and their location using a single algorithm run. Other object detection techniques in computer vision (e.g., DPP, Fast RCNN, and Faster RCNN) do hundreds of algorithm runs to arrive at a similar output. This gives YOLO certain notable advantages over other object detection techniques, top among them: speed. This is what makes YOLO a real-time object detection algorithm.
Why the Speed of Object Detection Is a Game-Changer
Before YOLO, models like Region-based Convolutional Neural Networks (R-CNN) and Deformity Parts Models (DPP) dominated the object detection space. DPP takes up to 14 seconds to detect all objects in an image, processing around 0.07 frames per second (FPS). R-CNN takes around six seconds more than DPP processing around 0.05 FPS. Here’s how YOLO changes the game: it can process as many as 65 FPS on a V100 GPU, detecting all objects in an image with considerable accuracy in just 22 milliseconds.
Now, imagine a self-driving car using DPP or R-CNN. If the vehicle was traveling on the freeway at 60mph, and the algorithm took 20 seconds to detect objects on the road like people and other cars, it would have traveled 0.3 miles or over 500 meters. This would make collisions practically impossible to avoid. The typical distance from one car to another on the freeway is 3 meters (10 ft). Real-time object detection that can be used in self-driving cars must detect objects before the vehicle covers the 3 meters traveling at a relatively high speed. In the 60mph example, YOLO would identify the objects before the car moves a meter, making it a truly real-time object detection algorithm.
YOLO includes two main parts: training and detection.
Let’s say you’re working on an image classification program to decide if an image you have is of a cat or a person. In this case, the neural network’s output is pretty simple; you will set the cat class as 1 and the person class as 0.

YOLO’s object localization uses bounding boxes to tell the object’s position in the image. Consider the image below:

Pc = Probability of the class (It’ll be 1 if there’s a cat or a person and 0 if there’s no cat or person.)
Bx and By = Coordinates of the center of the bounding box indicated with the yellow dot.
Bw and Bh = The width and height of the red bounding box.
C1 and C2 = The cat class and the person class. In this case, C1 is 1 because there’s a cat in the image, and C2 is 0 because there’s no person in the image.
A different image that has a person and no cat would have different neural network outputs, as illustrated in the image below:

In this case, C1 will be 0 because there’s no cat, and C2 will be 1 because there’s a person.
In the image below, where there’s neither a cat nor a person, Pc will be 0, and the rest of the values don’t matter.

This is how you train a neural network to classify objects and bounding boxes using thousands upon thousands of examples. As a result, when you introduce a new image, the algorithm can use the training to identify the objects therein and their positions in the image.
In scenarios where there are multiple objects in an image, YOLO divides the image into SxS grid cells and comes up with the vector for each grid cell. The object’s center determines which grid cell it’ll be classified as being part of.

Each cell predicts several bounding boxes giving each box a confidence score. The confidence score represents the algorithm’s level of confidence that an object exists in that bounding box. The scores range from 0.0 (the lowest level of confidence) to 1.0 (the highest level of confidence).
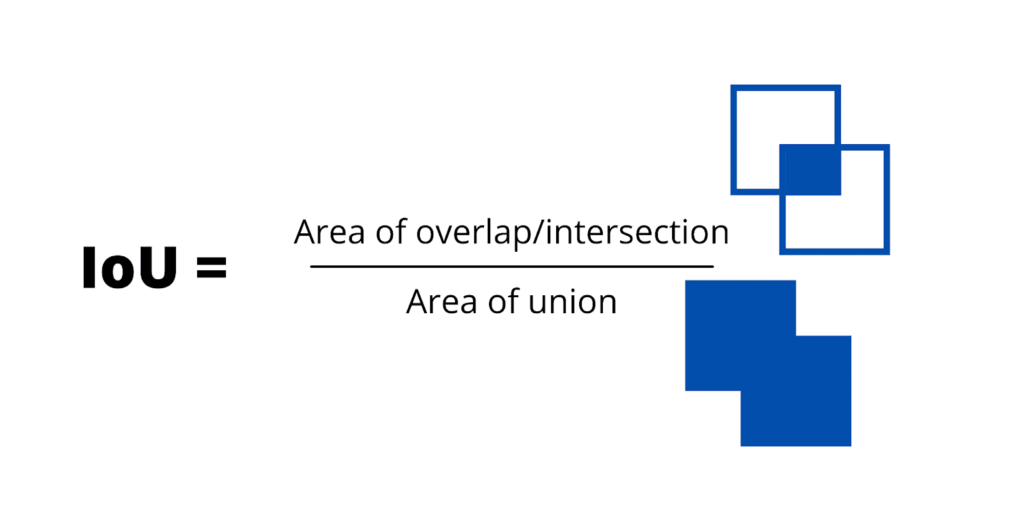
The confidence represents what is referred to as the Intersection over Union (IoU) between the actual bounding box and the predicted bounding box. It is calculated by dividing the overlapping area between the ground truth and predicted boxes with the area of the union of the two boxes.
Even though YOLO is an excellent object detection algorithm, it has its limitations. Perhaps its most significant limitation is that it can only identify one class of objects for each cell. So, if more than one object is in a single cell, the algorithm fails to classify them correctly.
Another limitation is that it may miss small objects entirely. YOLO struggles to place small objects (e.g., birds) into bounding boxes and classify them. Instead of placing them at the center of the cell, it might place them away from the center (e.g., the edge) and give them a low confidence score. The result will be concluding that there’s no object altogether.
Benefits of Using YOLO for Objection Detection
Let’s recap some of the benefits of YOLO in object detection:
- YOLO is extremely fast, making real-time object detection possible.
- How it is trained, and its architecture make YOLO a highly generalized network. This means it can identify generalized representations of objects, e.g., paintings of people and animals. As a result, when the algorithm is applied to unfamiliar situations and unexpected inputs, there’s a good chance it’ll still classify them.
- YOLO is contextually aware – doesn’t look at objects in isolation but considers their contextual information. Therefore, for instance, it would not mistake background noise for an object, e.g., a shadow that looks like a car for a car.
YOLO has come a long way since Joseph Redmon first proposed it in Darknet. Joseph Redmon wrote the first three versions: YOLO, YOLOv2, and YOLOv3. Joseph Redmon wrote both YOLOv2 and YOLOv3. After YOLOv3, other writers added their own objectives to each new YOLO release.
In April 2020, Alexey Bochkovski presented YOLOv4 with novel improvements that included enhanced feature aggregation and mind activation. Two months later, Glenn Jocher introduced YOLOv5, focusing on the algorithm’s architecture.
The invention of the YOLO algorithm revolutionized computer vision. It enjoys large-scale applicability and many use cases, including self-driving cars, intelligent video analytics, wildlife detection, etc. As a result, it’s poised for tremendous growth in the near future and brings a lot of promise for artificial intelligence and deep learning.


