

우리 인간들은 식빵과 웰시코기를 쉽게 구분할 수 있지만(사실 인간도 좀 힘듭니다..) 인공지능에게 이미지를 판별하는 것은 아직 어려운 일입니다. 그렇기 때문에 우리는 인터넷 속에서 종종 ‘캡챠(CAPTCHA)’를 만나곤 합니다.

‘캡챠(CAPTCHA)’란 어떤한 이용자가 실제 사람인지 컴퓨터 프로그램인지를 구별하기 위해 사용되는 방법으로, 사람은 구별할 수 있지만
컴퓨터는 구별하기 힘들게 의도적으로 비틀거나 덧칠한 그림을 주고 그 그림에 쓰여있는 내용을 물어보는 방법이 자주 사용됩니다. 흔히
웹사이트 회원가입을 할 때 뜨는 자동 가입 방지 프로그램은 같은 곳에 쓰이고 있습니다.
(출처: 위키백과 https://ko.wikipedia.org/wiki/CAPTCHA)

종종 튀어나와 우리를 귀찮게 만들던 이미지들이 인공지능의 약점을 이용한 것이라니 놀랍군요. 앞으로 귀찮은 캡챠가 뜨더라도 인간으로서의 긍지와 자부심을 가지고 즐거운 마음으로 임해야겠습니다. 이렇게 세상 스마트한 미래의 중심일 줄 알았던 인공지능은 아직 생각보다 덜 똑똑하고 인간의 지능을 따라잡기에는 갈 길이 멀어 보입니다.

코드(Code), 데이터(Data), 모델(Model), 알고리즘(Algorithm) 등 좋은 인공지능을 만들기 위해 필요한 다양한 요소들이 있지만 그 가운데 ‘데이터’의 중요성이 대두되고 있습니다. AI 4대 천왕으로 불리는 앤드류 응 교수는 21년 3월에 진행되었던 강연에서 ‘데이터’의 중요성에 대해 강조했습니다.

AI 시스템은 크게 코드와 데이터로 이루어져 있습니다. 이 시스템에서 AI를 학습시키는 과정 중 어떤 문제가 발생했을 때 우리에게는 두 가지의 선택지가 있습니다. 모델을 바꾸는 방법(model-centric AI)과 데이터를 바꾸는 방법(data-centric AI)이죠. 이 두 가지 방법 중 앤드류 응 교수팀의 연구에서는 데이터를 개선하는 것이 훨씬 효율적이라는 결과를 도출했습니다.
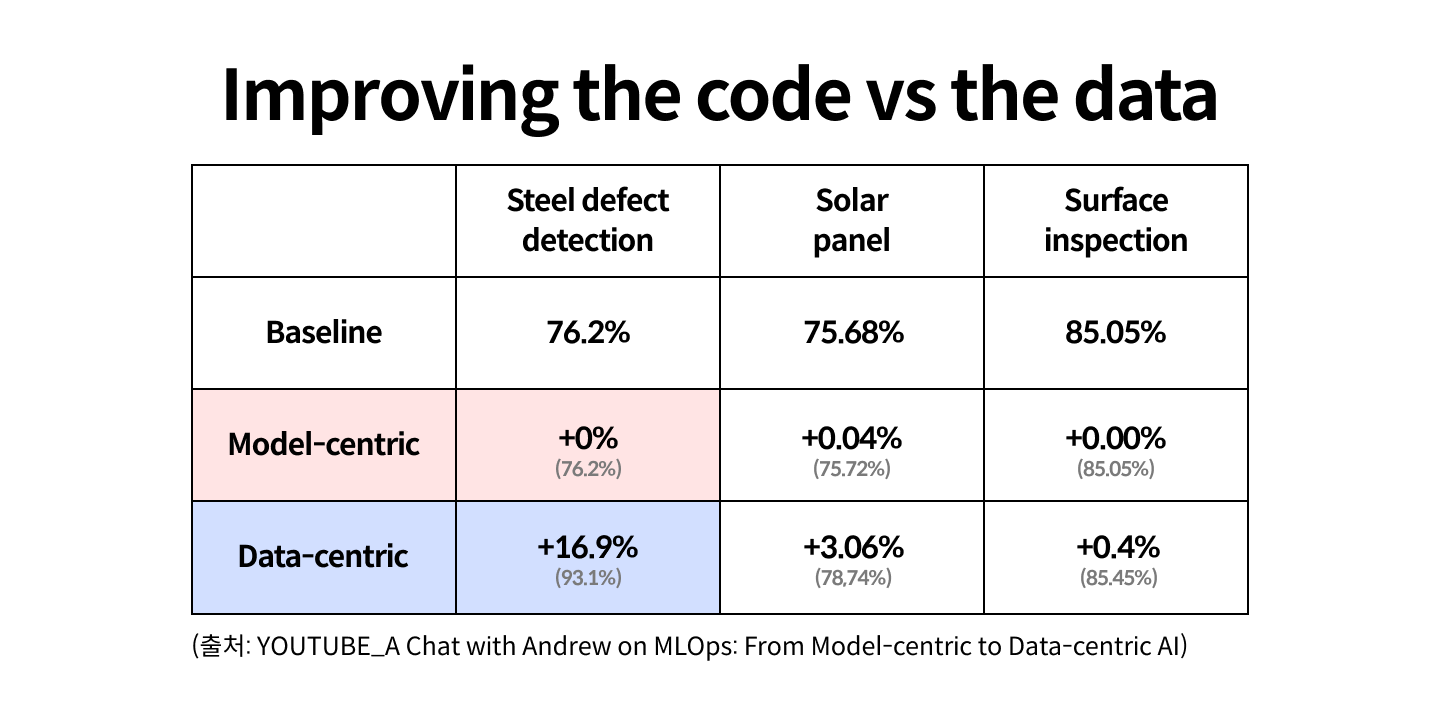
철 생산 과정에서 발생하는 불량을 탐지하는 시스템을 머신러닝으로 개발하며 발생하는 문제에 대해 연구팀은 모델을 바꾸는 방법과 데이터를 바꾸는 방법을 각각 진행했습니다. 그 결과 첫 번째로 만들었던 데이터로 학습을 시켰던 정확도(Baseline / 76.2%)에 대해 모델을 바꾸는 방법은 거의 성과가 없었으나 데이터를 바꾼 경우 그 정확도가 16.9% 증가한 것을 확인할 수 있었습니다. 그렇기 때문에 이전까지는 벤치마크 데이터셋에 대해 모델을 좋게 만드는 것에 집중했다면 이제는 데이터를 좋게 만드는데 집중해야 한다는 것을 강조했습니다.
고품질의 데이터를 수집하는 데 있어 Consistency(일관성)이 가장 중요합니다. 다양한 데이터를 수집하는 과정에서 보통 여러 명의 작업자가 데이터를 수집하는데 모두가 공유하고 있는 하나의 기준이 있어야 AI가 제대로 된 학습을 할 수 있기 때문입니다. 앤드류 응 교수는 이를 뒷받침하기 위해 음성 인식을 위한 데이터 수집을 예로 들었습니다.
 “Umm.. today’s weather?”이라는 음성을 듣는다면 여러분은 어떻게 받아 적으실 것 같나요?
“Umm.. today’s weather?”이라는 음성을 듣는다면 여러분은 어떻게 받아 적으실 것 같나요?
감탄사를 적어야 할지, 감탄사 뒤에 어떤 문장부호를 적어야 할지, 그냥 문장만 적어야 할지 여러 명의 작업자가 함께 공유하고 있는 명확한
기준이 없다면 정말 다양한 방법으로 적혀진 문장이 수집될 것입니다.
Umm, today’s weather
Umm… today’s weather
Today’s weather
세 가지 문장 모두 데이터로 만드는 방법이 가능하지만 문제는 이 음성에 대해 인공지능을 학습시켰을 때 셋 중 하나를 꾸준히 학습시켜야
일관성을 가질 수 있다는 것이죠. 만약 세 가지 문장 모두 데이터로 만들게 된다면 노이즈가 발생하게 됩니다. 일관된 고품질의 데이터를 얻기 위해서는 동일한 작업을 여러 작업자에게 맡겨 작업의 일관성을 재고, 동일한 결과가 나올 수 있도록 레이블링 가이드를 수정해야 합니다.
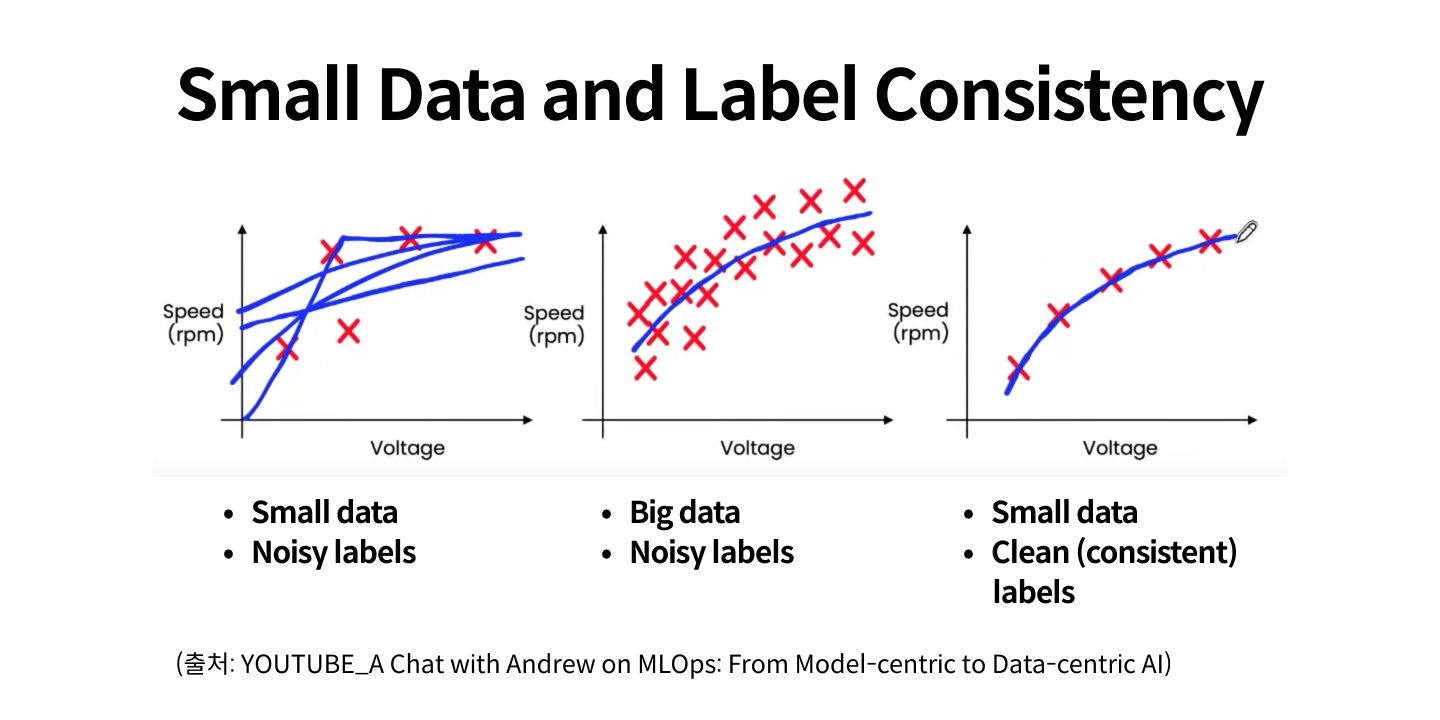
위의 표에서 큰 데이터의 경우 노이즈가 있더라도 그 수가 많기 때문에 어느 정도 일관된 결과를 얻을 수 있는 반면 작은 데이터에 노이즈가
많은 경우 결과가 갈피를 잡지 못하고 일관성을 잃는 것을 확인할 수 있습니다. 적은 수의 데이터일수록 노이즈의 영향이 크기 때문에 클린하고 일관성있는 레이블이 중요합니다.
이러한 문제를 해결하기 위해 셀렉트스타는 자체 개발한 수학적 알고리즘을 적용한 첨단 데이터 검수 시스템을 통해 확장 가능하고 강력한
크라우드소싱 플랫폼 캐시미션을 제공합니다. 또한 반자동 레이블링을 통한 편리한 데이터 가공 환경을 제공하고 유사성 검사를 통해 비슷한 데이터를 필터링하는 등 똑똑한 AI가 도와주는 데이터 수집과 가공으로 효율적이고 효과적인 결과를 제공하고 있습니다.
다양한 기업들과 여러 대학 연구실에서 지원 사업에 참여하여, 셀렉트스타를 통해 무료로 데이터셋을 구축하였고, 더 나은 AI를 위해 더 많은 이들에게 양질의 데이터를 제공하고자 ‘오픈데이터셋’을 통해 데이터를 공개하였으며 현재 다운로드가 가능합니다.
데이터를 통해 IT 산업을 발전시켜 더 편한 세상을 만들기 위해 셀렉트스타는 오늘도 열심히 움직이고 있습니다.
