
🔑 In 9 minutes you will learn:
- In this tutorial, we are going to talk about online image crawling and some of the common problems that we come across while doing so.
Online image crawling is basically a way of gathering large amounts of images through different websites. In short, we scrape images from different web pages, store them in a folder, drive or any desired location, and can use those images for different purposes, like for building an image dataset for a machine learning model. So in this tutorial, we will be discussing two ways of online image crawling, one through a Google Chrome extension named Fatkun Batch Download Image and another by writing Python script to scrape images from a web page. The main topic that we will be going through is the common problems incurred while scraping images from the web. So let’s get started!
Scraping Images from the Web
Google Chrome’s Fatkun Batch Download Image Extension
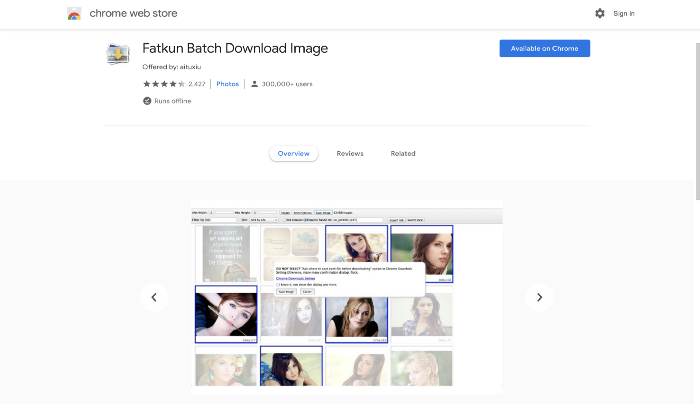
Fatkun Batch Image download is a simple and useful image download extension. As its name suggests, it allows you to download images in a batch from a website and use them for different purposes. You can apply search filters, select and deselect images, opt for a particular tab or all tabs for image download, rename images in batch, and can also vary image sizes before downloading them. For more about this extension i.e. for installing it, setting it up, and using it, you can read the ‘Downloading images through the Fatkun Batch Download Image extension’ section in our Creating the Best Quality Image Dataset article.
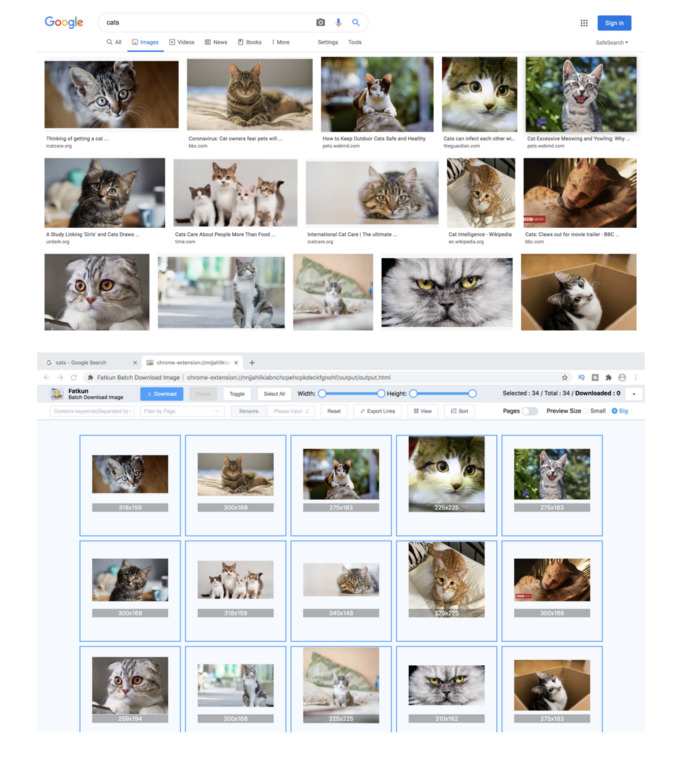
Drawbacks of this extension:
- Tedious when it comes to collecting images for large datasets.
- Images collected are thumbnails and not original size images.
Image Crawling in Python
There are multiple Python packages and libraries that can help you to scrape images from a website. These include Beautiful Soup, Selenium, Scrapy, etc. We will be talking about Scrapy which is basically a framework written in Python and designed for web scraping. It can also be used to extract data using APIs or just as a general-purpose web crawler. For more details on this framework and for full-fledged implementation of it for large-scale image scraping for datasets, you can have a look at our Custom Dataset Creation with Web Scraping article.
Problems of Online Image Crawling
Online image crawling or scraping is an important aspect for gathering relevant images from different websites especially when it comes to building high-quality image datasets for different machine learning models to be trained on. However, scraping images from the web is not without its challenges. The context of the internet changes with each passing day, making it complicated and at times almost impossible to successfully gather images from different websites. Even if you succeed in doing so, the performance of the web scraper may be seriously compromised. So it’s extremely important to consider certain factors before diving into the scraping process itself. Let’s have a look at some of the common problems that one could come across while scraping images online:
1. Access to scraping:
Before you plan on scraping images or other content from a particular website, it is important for you to ensure that the target website permits scraping. This is because many applications restrict access through their robots.txt file. A robots.txt file basically tells search engine crawlers which pages or files the crawler can or cannot request from your site. In case, if access for image crawling has been denied to you, you can through a formal or informal route, contact the owner of the website, explain your situation and request him/her for access. If that does not work out, you can look for other websites with similar content and hope for the best.
2. Anti-scraping policies:
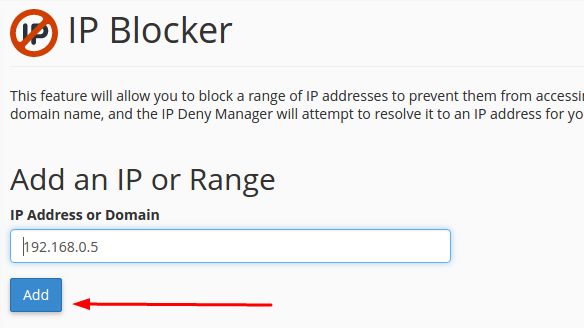
Another common problem which you can come across while trying to scrape images from a website is its anti-scraping policy. For instance, to prevent the scraping of their content, many websites make use of IP blocking. This is a way of preventing someone from scraping the content of your website by banning the scraper’s IP address or restricting it to slow down the scraping process. This occurs when the target website detects a high number of requests coming from the same IP address, which is usually the case in online image crawling since mostly a large number of images are being scraped at one time. The website considers it as a malicious activity and retorts to IP blocking. One fine solution to this problem is Octoparse Cloud Service which uses multiple IP addresses to scrape one website at the same time and thereby prevents IP blocking.
3. Diversity in website structures and layouts:

Web scrapers have some generic limitations that cannot be overcome. Each web scraper is tailored to perfectly suit one particular website and cannot be used for every other website to scrape images. This is because websites have different structures, characteristics. formats and layouts. So there is no general web scraper which fits all websites, rather particular ones for each website. It is also common for not only websites but also webpages to have different structures and layouts from each other. This is because web page designers design different web pages according to their own tastes and standards. This also makes online image crawling an extremely tedious task considering the fact that you have to make changes to your web crawler in accordance with different websites or web pages in order to scrape images from them.
4. Continuously changing website content:
Many websites update their content continuously by adding new features, removing unnecessary features, making certain layout and design changes, etc. This is done to improve user experience but can greatly affect the performance of the web scraper. Since each web scraper is specific to a website, any change in that website in turn is a call for changes in the implementation of the web scraper as well. Even if the website change is extremely minor, it might require you to adjust the scraper accordingly and that can be challenging at times. Octoparse Cloud Service again helps in visualizing these changing structures so that the image crawler can be altered accordingly.
5. Bad Image Quality:

Image quality is an extremely important factor especially when we are talking about building image datasets. The quality of your scraped images can be seriously compromised due to any technical weaknesses or shortcomings of your web scraper. Therefore, it is pivotal for you to choose a high-quality web scraper with a lot of good features to do the job.
6. Slow loading of Website:

Websites may respond very slowly or even fail to load because they may be receiving too many access requests which can be a serious problem in online image crawling.
7. Geographical restrictions:
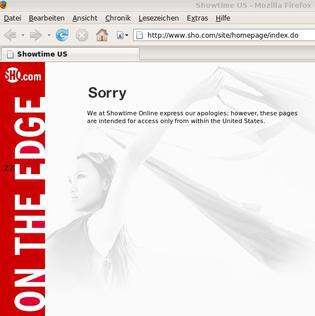
At times, the biggest hindrance to online image crawling can be your location, since some websites may not be accessible or may not permit scrapping of their content in certain regions or countries.
Online image crawling is often not enough for companies to train their industry-level algorithms. Moreover, it is difficult to control the quality within a company, especially your company is a small- or medium-sized company. Therefore, it is often more efficient to find another service that does laborious works for you. We could be your perfect solution!
Here at DATUMO, we crowdsource our tasks to diverse users located globally to ensure the quality and quantity on time. Moreover, our in-house managers double-check the quality of the collected or processed data. If you need data? If you need preprocessed data? Let us know!
To sum it all up, we started off by discussing what online image crawling is and then briefly touched upon how it can be done through Fatkun Batch Image Download extension and by using Python’s Scrapy framework. We discussed the common problems of online image crawling in general like the bad quality of data, anti-scraping policies etc. We suggested solutions for some of them as well and learned that while some of the problems were easily solvable, others were not.


